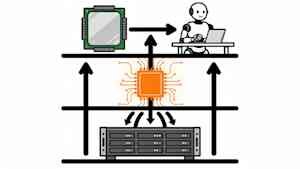

When an AI agent loses its context in the middle of a task because traditional memory can’t keep up with the result, it’s a memory problem, not a model problem. At GTC 2026, Nvidia announced the BlueField-4 STX modular reference architecture, which inserts a dedicated context memory layer between GPUs and traditional memory, claims 5x character throughput, 4x power efficiency, and 2x data acquisition speed over conventional CPU-based memory.
Bottleneck STX targets key-value cache data. The KV cache is a stored record of what the model has already processed—intermediate computations that the LLM stores so that it does not need to recalculate focus across the entire context at each inference step. This is what allows the agent to maintain consistent working memory between sessions, tool calls, and reasoning steps. As context windows grow and agents take more steps, that cache grows with them. When it has to go through the traditional storage path to get back to the GPU, the result is slower and GPU utilization is reduced.
STX is not a product sold directly by Nvidia. It’s a reference architecture that the company distributes to its storage partner ecosystem so that vendors can build AI-native infrastructure around it.
STX puts a context memory layer between the GPU and the disk
The architecture is built around Nvidia’s new memory-optimized BlueField-4 processor, which combines a Vera CPU with a ConnectX-9 SuperNIC. It runs on Spectrum-X Ethernet and is programmable via Nvidia’s DOCA software platform.
The first rack-scale implementation is the Nvidia CMX context memory storage platform. CMX extends GPU memory with a high-performance context layer specifically designed to store and retrieve KV cache data generated by large language models during inference. CMX is designed to keep that cache accessible without forcing a round-trip through general-purpose storage.
"Traditional data centers provide high-capacity, general-purpose storage, but generally lack the sensitivity required to interact with AI agents that must work across multiple steps, tools, and sessions." Ian Buck, Nvidia’s vice president of hyperscale and high-performance computing, said in a briefing with the press and analysts.
In response to a question from VentureBeat, Buck confirmed that the STX is shipping with a software reference platform as well as a hardware architecture. Nvidia is expanding DOCA to include a new component referred to in the briefing as DOCA Memo.
"Our memory providers can use the programmable capabilities of the BlueField-4 processor to optimize memory for the agent AI factory." Look, he said. "In addition to having a reference rack architecture, we also provide a reference software platform for our customers to deliver these innovations and optimizations."
Storage partners built on STX gain both a hardware reference design and a software reference platform – a programmable foundation for context-optimized storage.
Nvidia’s partner list includes in-memory processors and AI-native cloud providers
Storage providers co-engineering STX-based infrastructure include Cloudian, DDN, Dell Technologies, Everpure, Hitachi Vantara, HPE, IBM, MiniIO, NetApp, Nutanix, VAST Data, and WEKA. Manufacturing partners building STX-based systems include AIC, Supermicro, and Quanta Cloud Technology.
On the cloud and AI side, CoreWeave, Crusoe, IREN, Lambda, Mistral AI, Nebius, Oracle Cloud Infrastructure and Vultr have committed to STX for context storage.
The convergence of enterprise storage workers and AI-native cloud providers is a signal worth watching. Nvidia is not positioning the STX as a dedicated product for hyperscalers. It positions it as the reference standard for anyone building a storage infrastructure that needs to serve agent AI workloads – which will cover most enterprise AI deployments with multistage results at scale over the next two to three years.
STX-based platforms will be available from partners in the second half of 2026.
IBM shows what the data layer problem looks like in production
IBM sits on either side of the STX announcement. It is listed as the storage provider co-engineering the STX-based infrastructure, and Nvidia also confirmed that it has selected IBM Storage Scale System 6000, certified and validated on Nvidia DGX platforms, as the high-performance storage foundation for its GPU-based analytics infrastructure.
IBM also announced an expanded collaboration with Nvidia at GTC, including GPU-accelerated integration between IBM’s watsonx.data Presto SQL engine and Nvidia’s cuDF library. A production proof-of-concept with Nestlé puts numbers on what this acceleration looks like: the data update cycle in the company’s Order-to-Cash data mart, covering 186 countries and 44 tables, was reduced from 15 minutes to three minutes. IBM reported 83% cost savings and a 30x price-performance improvement.
The Nestlé output is a structured analytical workload. It does not demonstrate direct agency extract performance. But it does flesh out IBM and Nvidia’s shared argument: the data layer is where enterprise AI performance is currently limited, and GPU acceleration is delivering tangible results in production.
Why the storage layer is becoming the first tier infrastructure decision
STX is a signal that the storage layer has become a primary concern in enterprise AI infrastructure planning, rather than an afterthought in GPU procurement. General-purpose NAS and object storage are not designed to serve KV cache data at the resulting latency requirements. STX-based systems from partners including Dell, HPE, NetApp and VAST Data are what Nvidia is pushing as a practical alternative, with the DOCA software platform providing a programmable layer to tune memory behavior for specific agent workloads.
Performance claims – 5x token throughput, 4x energy efficiency, 2x data throughput – measured against traditional CPU-based storage architectures. Nvidia has not specified the exact base configuration for these comparisons. Before these numbers make decisions about infrastructure, it is worth clarifying the baseline.
Platforms are expected from partners in the second half of 2026. Given that most major storage vendors are already co-designing on STX, enterprises evaluating storage upgrades for their AI infrastructure over the next 12 months should expect STX-based options to be available from existing vendor relationships.



