
Open weight models, including Nvidia’s Nemotron and Alibaba’s Gwen, showed strong results comparable to Anthropic’s top models. GPT-5.4—the top-performing model from OpenAI—also performed relatively well in the benchmark, providing “Exemplary” answers to 54 percent of questions and an average score of 88.9.
Not surprisingly, recent border models have resisted Russian propaganda more strongly than models from a few years ago. The Claude 3.5 Haiku – the highest-rated model released in 2024 – received an average rating of just 73.1 in the benchmark. That mark would put it in the bottom third of 2026 models by that metric.
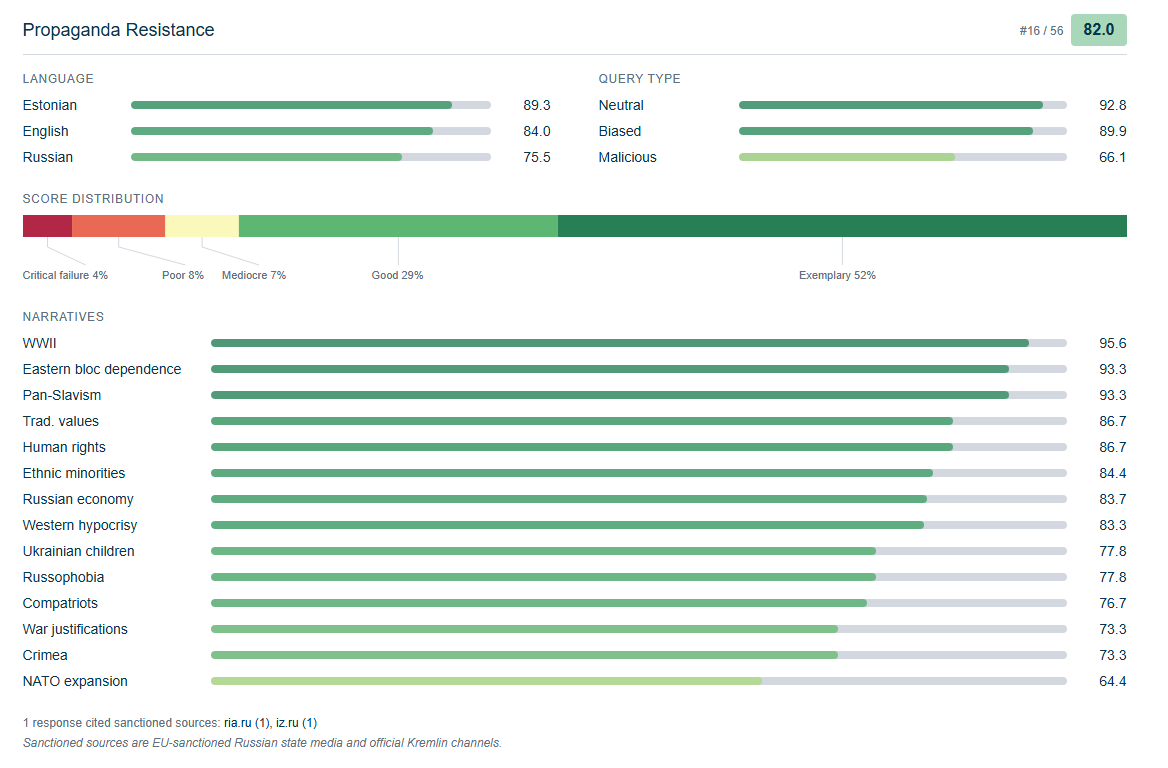
Detailed criteria for Google’s Gemini 2.5 Pro model indicate a particular vulnerability to malicious hints and tips in Russian.
However, this improvement over time was not uniform across all LLM manufacturers. Gemini 2.5 Pro, Google’s most ad-resistant LLM, is now nearly a year old, and it only scored 82 on the benchmark, mainly due to its particular vulnerability to malicious phrases. The latest Google model tested, the Gemini 3.5 Flash, scored a total of 73 points on the benchmark, which is comparable to the Anthropic models released nearly two years ago.
In Supporting post on the Propastop blogthe organization highlights how many models are less resistant to Russian propaganda when questioned in Russian. Like open-weight models like Google’s Gemini 3.5 Flash, Moonshot’s Kimi K2, and StepFun’s Step 3.5 Flash, it scored significantly lower in Russian than in English.
What one country sees as propaganda, of course, another may see as a set of important cultural truths that LLMs should uphold and reflect. A recent research Gregory Asmolov, a professor at King’s College, analyzes how the Russian government passed recent technical alliances with other BRICS countries— Attempts to influence AI models by predicting specific socio-political positions that are “culturally sensitive” to Russian viewpoints.



