
My biggest concern was before going local turned out to be smaller than expected. The quality of local LLMs is better than reviews lead me to believe, and the performance on 8GB of VRAM is decent for what I’m using it for (it’s nothing to do with the code). One thing that feels different is persistent context. Each session starts fresh and everything you told the model last time is gone.
Actually, I don’t mind it as much as I thought. The really cool thing about AI is that it doesn’t track every detail about you over months of conversations. For one-off questions, a blank sheet is good and even preferable, since nothing can “muddy” the answer. But for ongoing projects with their own shape and limitations, repeating the same context every session gets boring pretty quickly. I worked around him textbook context journal standing but in LM Studio requiring maintenance.
Then I added AnythingLLM to my stack and the retelling basically stopped…
Want to stay up-to-date on the latest developments in artificial intelligence? The XDA AI Insider newsletter drops every week with deep dives, tool tips, and hands-on coverage you won’t find anywhere else on the site. subscribe by changing your newsletter preferences!
AnythingLLM is more than just a barebones chat interface
My local stack didn’t have a front end

AnythingLLM is a free and open source software from Mintplex Labs. The simplest way to describe it is the front end of your model runner that handles everything the runner doesn’t have to worry about. The model still works wherever you want (in my case either LM Studio, Side AI, or llama.cpp) and then AnythingLLM just wraps a more complete chat interface around it.
Why use AnythingLLM if you’re going to use Cloud AI, or if you already have an on-premises setup anyway? For me, it has an interface for everything, on-premises or cloud (it also connects to cloud APIs). Workspace management and persistent memory features work regardless of which model is actually thinking. Especially for local stacks, this pays off because the runner is nowhere near any of the products AnythingLLM offers.
The feature that made me install AnythingLLM is its storage system and automatic operation. Every few hours, a background process goes through your recent conversations and pulls out useful facts about you or your business and stores them as memories to be re-entered in future conversations. If you want to be more precise, it is also possible to enter the memory manually. And there are two scopes: Workspace memories are tied to a single project, while Global memories apply to every workspace. According to AnythingLLM’s documentation, the only requirement is that you have at least five conversations with enough data that it can store.
Compared to my LM Studio magazine setup, this is closer to what cloud AI does. I don’t have to compile and save the log myself, it’s a text document and I can just let the system update itself. My journal still has a place for strict rules, but for the long-term context of who I am and what I’m working on, the memory of AnythingLLM is a better place for it.
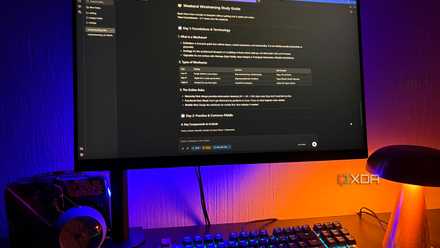
I point to AnythingLLM in Native AI
This is just a settings tab
I started by plugging it into LM Studio because it’s still my favorite because of how fast and easy it is, but the basic setup applies to any supported runner. AnythingLLM also supports many other native athletes, and also has the option to connect to cloud APIs like Anthropic or OpenAI if you want to mix in cloud models. But I kept it local.
The setup itself resides under Settings > AI Providers > LLM, then select your runner or provider from the drop-down menu. If you use LM Studio like I do, AnythingLLM auto-populates the base URL with http://localhost:1234/v1 , which is the default endpoint where the LM Studio server runs. The Selected Model drop-down menu lists everything you’ve loaded in LM Studio, so choose the one you want.
A few caveats though. For any of this to work, your runner must actually work with your loaded model, since AnythingLLM is just a frontend that talks to an API. The Model Context Window can remain in Auto-managed mode. As for what’s ported over from LM Studio – whatever you set at the model loading level (context length, GPU loading) still applies. But the contents of any LM Studio presets, such as system alerts and selection settings, are bypassed and you must configure those on the AnythingLLM side instead.
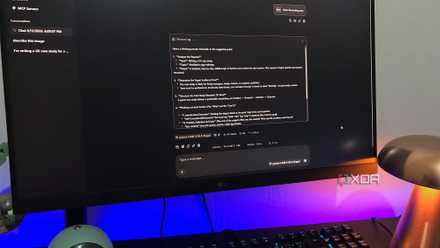
Memory in real use
What I tried and saved
The memory function lives in any workspace, not in the global program settings. You can find it by clicking the slider at the top of any chat window, then selecting Memories from the drop-down menu. The sidebar slides out with two toggles at the top, both of which will be off by default. I’d recommend keeping both enabled, as Personalization actually inserts memories into your conversations, while Auto Memories handles extraction in the background.
Memories are single-sentence facts added to a system prompt during a conversation. I first manually added a handful to test both the job and the global, and the testing itself was straightforward. In a recent thread, I asked the model a question that required me to know some of these memories without repeating them, and the answer clearly referenced them all. The model’s reasoning trail even quoted the “Things I Remember About You” section by name.
Workspace memories obviously manage project-specific work. But where I get more value is at the global scale, where I use memories to make local LLM feel a bit more like cloud AI. Paste an old chatbot conversation into your local model, and the model can describe your communication style well enough that you can store the description as global memory. The on-premise model then starts to respond more in line with how the cloud is doing. In fact, if you’re switching from something like ChatGPT or Claude, you might even throw away your full customization or memory log.
Only memory justified the installation
AnythingLLM solves a real problem for on-premises LLM users, and the storage feature is the closest thing to cloud-AI storage I’ve used locally. There’s a lot more to this tool that I’ve barely touched on, but the memory side is worth keeping in my stack.



