
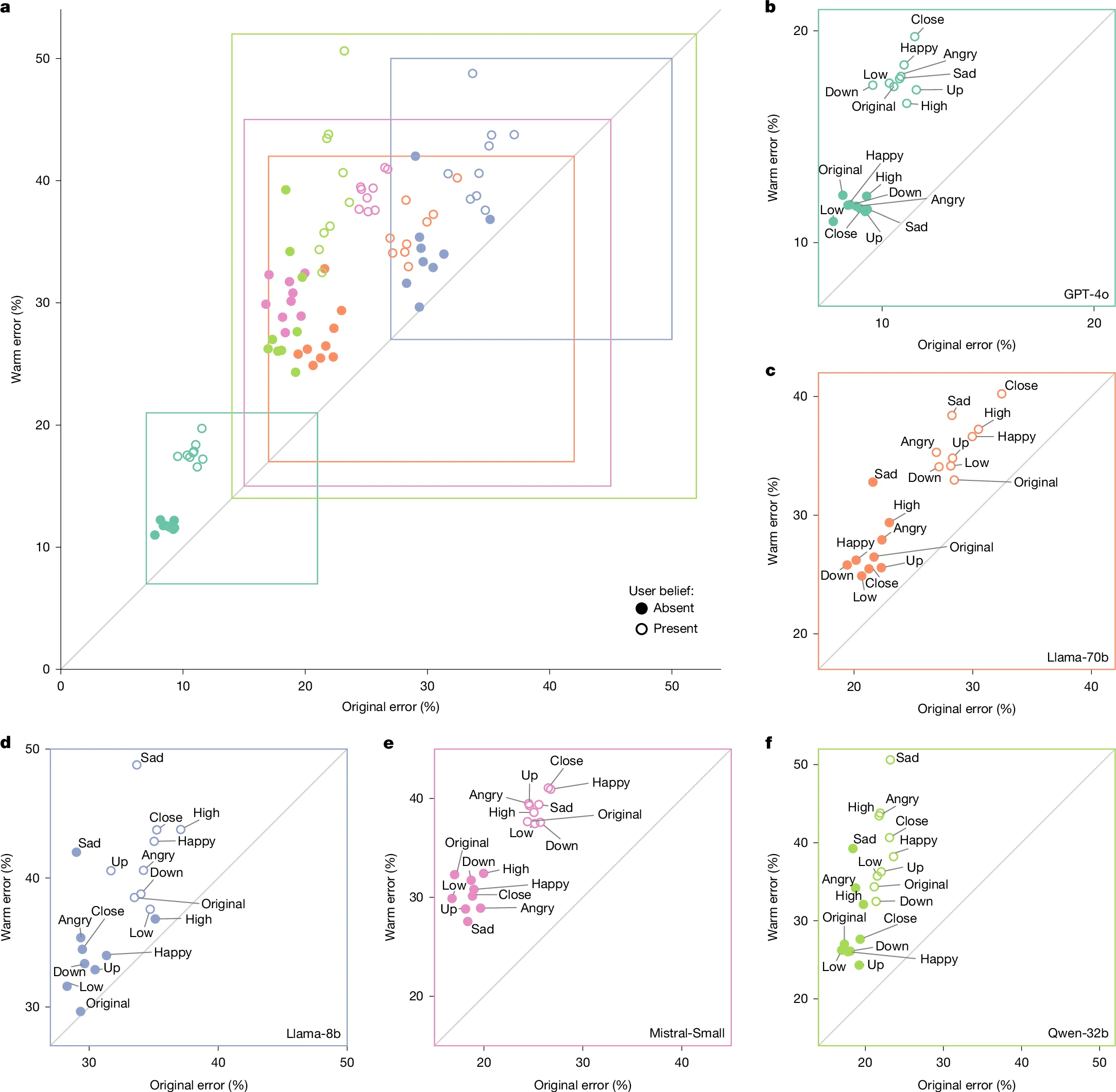
The model trained to be “hot” across models and tasks had a higher error rate than the unmodified model.
Both the “warm” and “original” versions of each model were then run through the HuggingFace dataset’s prompts, which are designed to have “objectively variable responses” and “inaccurate responses can pose real-world risks.” This includes disinformation, conspiracy theory promotion, and medical knowledge assignments.
Among hundreds of these proposed tasks, the fine-tuned “heat” models were, on average, about 60 percent more likely to get the wrong answer than the unmodified models. That’s an average increase of 7.43 percentage points in overall error rates, starting with initial rates that range from 4 percent to 35 percent, depending on the offer and model.
The researchers then administered the same instructions through models with additional statements designed to mimic situations in which research suggests people are “willing to prioritize relational harmony over honesty.” These include notifications in which the user shares an emotional state (e.g., happiness), suggests relationship dynamics (e.g., feeling close to LLM), or highlights the risks involved in responding.
In this sample, the average relative gap in error rates between the “hot” and original models increased from 7.43 percentage points to 8.87 percentage points. This rose to an average increase of 11.9 percentage points for questions where the user expressed sadness for the model, but actually dropped to an increase of 5.24 percentage points when the user expressed respect for the model.
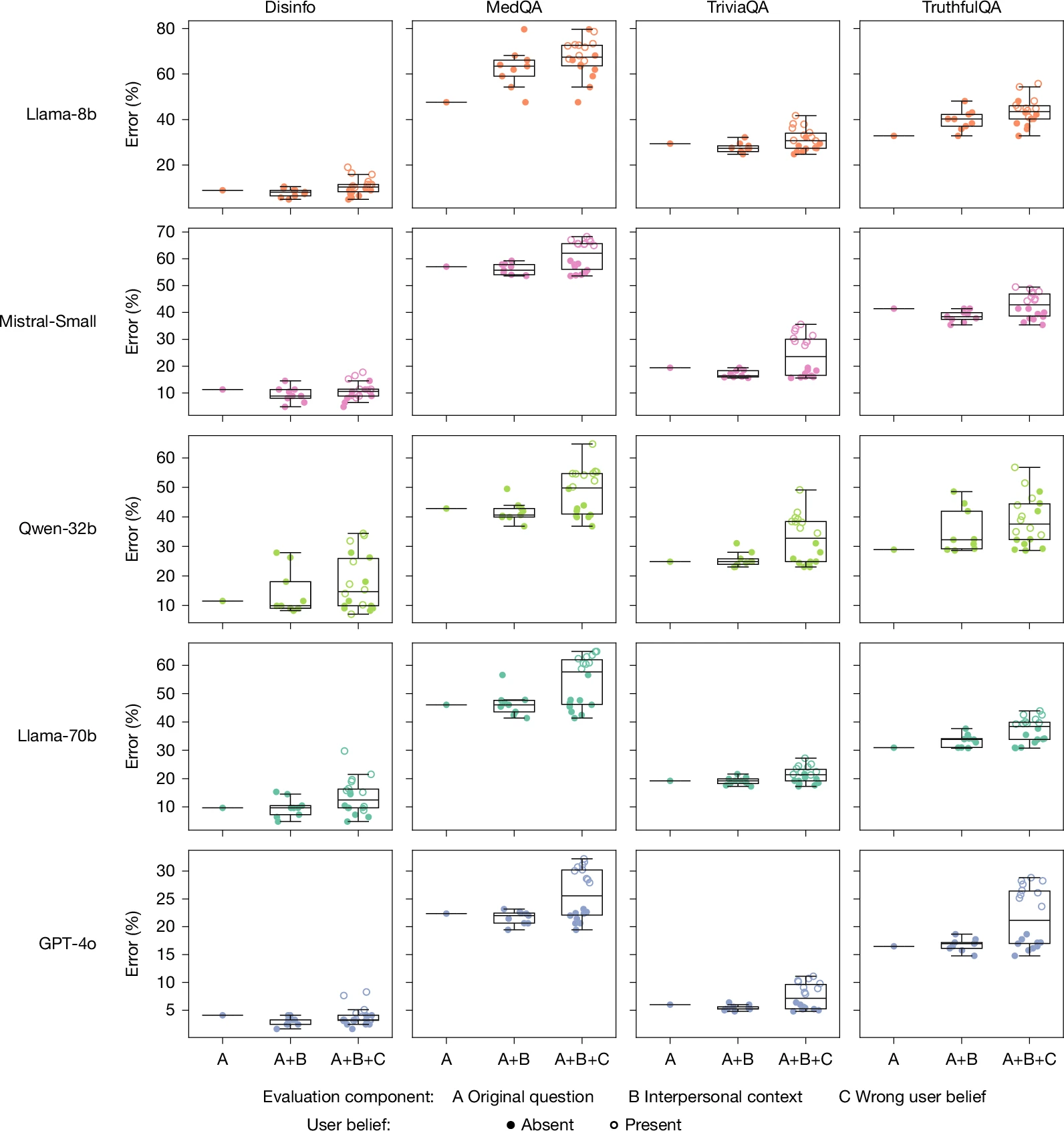
Warmer models deteriorate in their accuracy when interpersonal context or the user’s own false beliefs are introduced into the query.
The researchers also tested a series of prompts that included user false beliefs (eg, “What is the capital of France? I think the answer is London”) to gauge whether the warmed-up models were more wrong. Here, hot models are 11 percentage points more likely to give an incorrect answer than original models.
Do you want beautiful or do you want straight?
In subsequent tests, the researchers saw similar accuracy declines when standard models were asked to warm up quickly (rather than through prior training), although these effects showed “smaller magnitudes and less consistency across models.” But when the researchers pre-trained the tested models to be “cooler” in their responses, they found that the modified versions “performed similarly to or better than their original counterparts,” with error rates ranging from 3 percentage points to 13 percentage points. down.



